Information Gain.
A phenomenon researched extensively by the late and great Bill Slawski.
In this guide, we will explore the importance of information gain, as well as AI powered tactics you can use to boost the information gain of any page.
What is information gain?
Information gain is a measure of how much new information a particular piece of data provides. In the context of search engines, information gain can be used to rank search results based on how much new information each result provides to the user.
Bill Slawski identified that Google indeed patented scoring systems for information gain. And he often spoke of the benefits of improving the information gain of your page.
Essentially, if your page has unique and useful info not found on all the other pages, you get a high information gain score because the user gains lots of new and non-repetitive information from your page.
Bill’s research on information gain plays a key role for where search is headed.
Why information gain is important
Ensuring your page provides “information gain” is a key aspect to SEOing out here today. Because everyone and their grandma with her DR 90 site is pumping out AI content right now.
That means there are a lot more pages being built off the same information. The information gain scores are probably very similar.
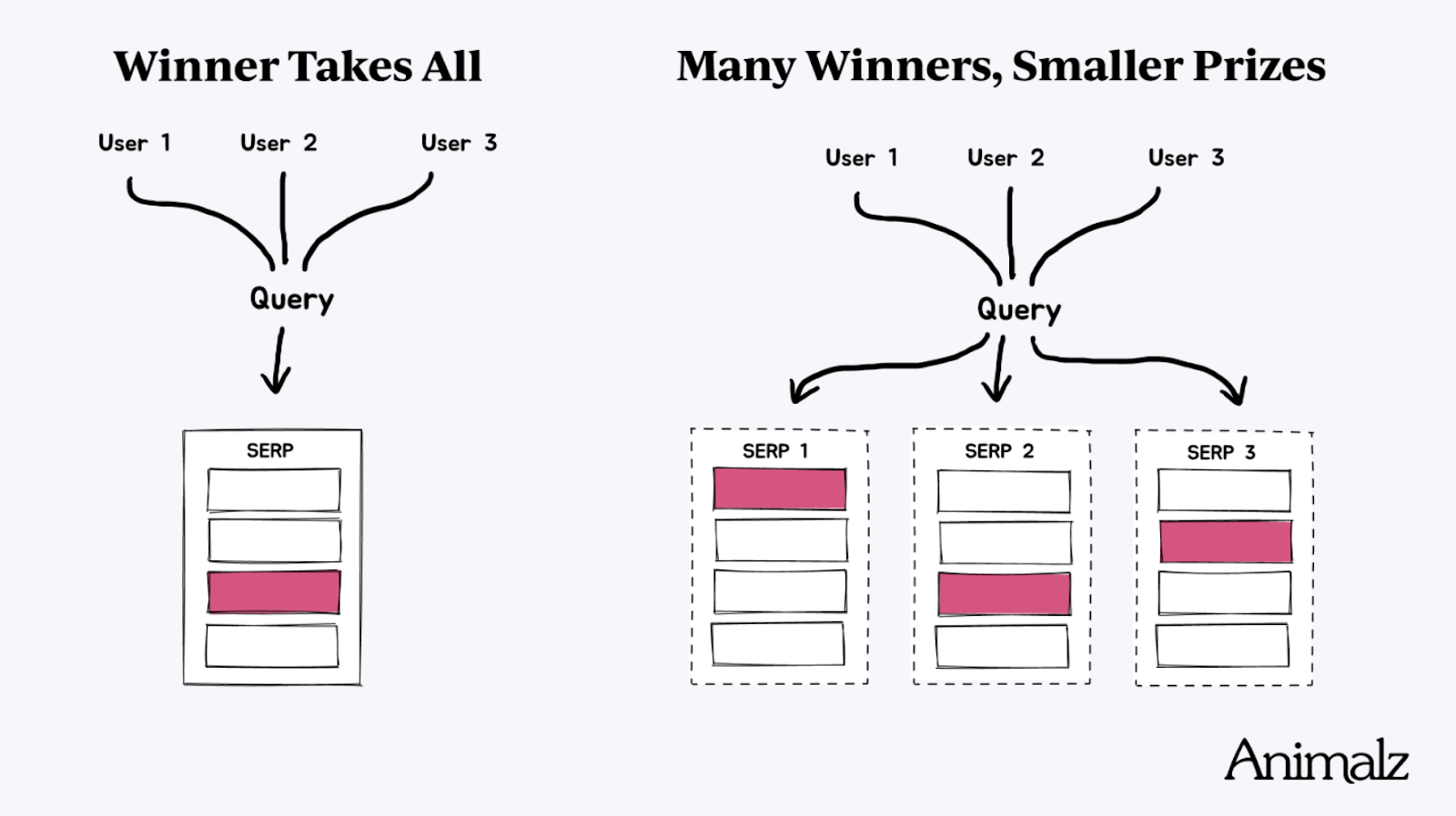
This diagram from Animalz sums it up nicely. Instead of one page taking all the rankings and traffic, we are seeing more pages win their own pieces of the pie based on the unique information they bring to the table.
So In summary, information gain = winning rankings.
The information gain advantage for non-content spammers
Grandma’s turbo-powered content app skips the important information gain factor. That’s where people who aren’t content spamming have an advantage.
(Until they add information gain features to their content spam apps 😅)
Currently, we can provide much more information gain to users than most of the other sites out there just by providing helpful info they won’t find anywhere else.
The only thing standing in the way is that dreaded E word…
Effort. Ew.
Information gain is hard, but now AI can do the heavy lifting
Information gain is a lot of work. In order to find the things that other pages aren’t talking about, you have to look outside of the same pages.
Most people don’t look much further than the top ranking search results when looking for content ideas to stea.. I mean, reference.
To succeed with information gain, you need to really explore the web to find those nuggets. And that takes time.
But thanks to AI, the heavy lifting can done for you. And little information gain nuggets can be served to you on a silver platter.
Let’s explore how to do that.
The Easy Way: Extract Information Gain From PDFs
PDFs are a great place to look for information gain. Whitepapers, reports, research, etc.
There are tons of PDFs on the web that contain rich information gain nuggets for just about any topic.
And most of the insights in these highly valuable documents don’t make their way into the wide web.
How to extract PDF
ChatGPT’s paid subscription (GPT Plus) comes with the new Code Interpreter feature. You can now upload PDFs directly to ChatGPT.
You will need GPT Plus for this tutorial.
Step 1: Finding valuable PDFs
It’s easy to find a PDF relevant to your page. Just take your target keyword and “[PDF]” and hit the SERPs.
For example, if you are working on a page about the cost of cryptocurrency mining, you would take your target keyword, “cost of cryptocurrency mining” and add [PDF] to that.
That becomes your search query: “cost of cryptocurrency mining [PDF]”.
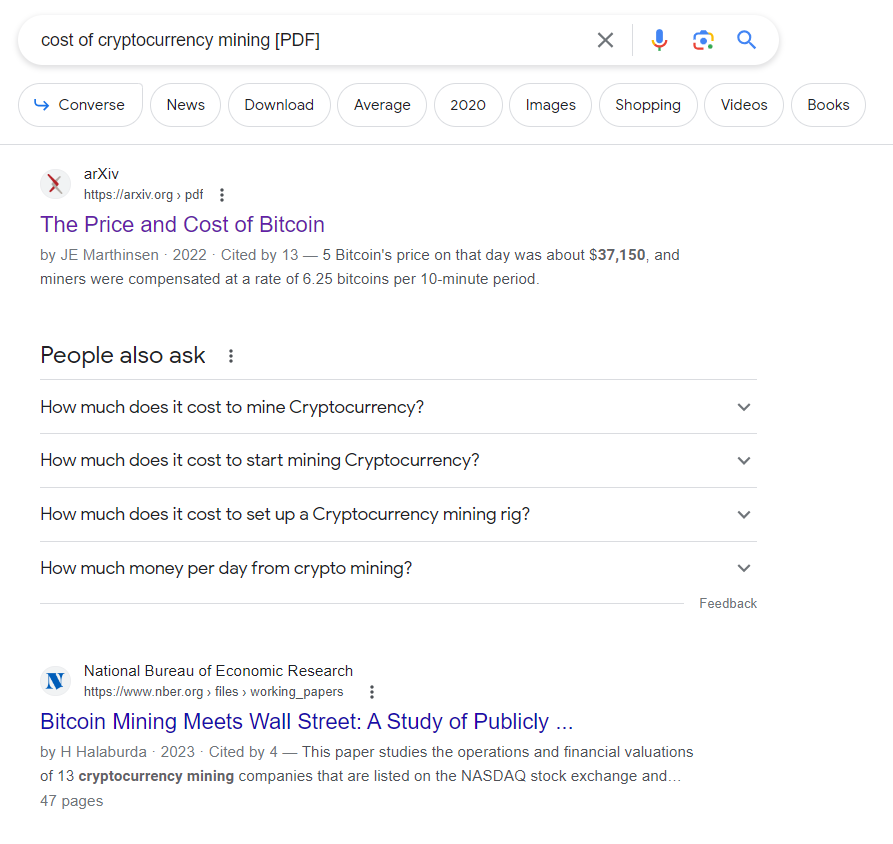
And viola, we have many PDFs to choose from. Let’s take the first result as an example.

This PDF talks about the price and cost of bitcoin, and mining plays a key role in the cost.
This is a good example because the information on mining is spread throughout the PDF.
We need to extract the good stuff.
Step 2: download your PDF and upload to ChatGPT
Download your PDF, and upload it to ChatGPT with the code interpreter feature enabled.
The Code Interpreter Plugin makes quick work of extracting the key information related to the target keyword.
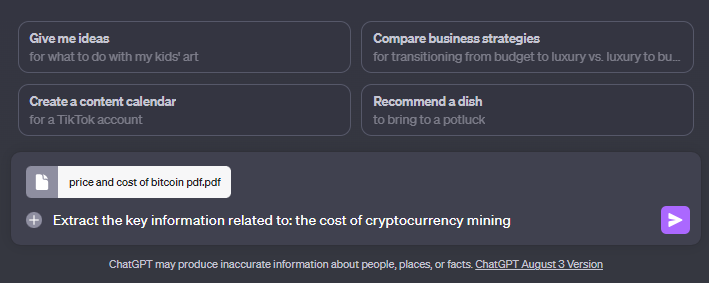
Prompt: "extract the key information related to: [TARGET KEYOWRD]"
ChatGPT will then work to extract the key information. The first iteration of output will not be very useful, but now that ChatGPT has the info we can continue extracting value.
Step 3: Prompt to provide 10 useful insights
"Provide 10 useful insights about [TARGET KEYWORD] from this PDF"
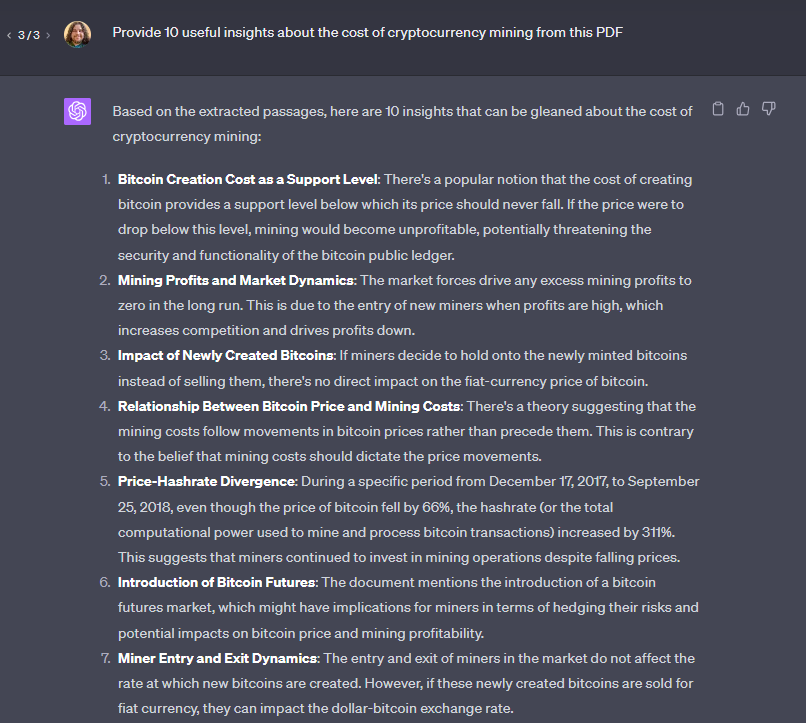
This prompt produces a nice list of insights. Simple and straight forward.
Now let’s check to see if any of these insights are on the first page for “cost of cryptocurrency mining”
Step 4: Prompt to check this page and compare to PDF
So you can also just use GPT to scan pages to see if they are using the useful insights found from the PDF. Just use this prompt:
"Check this page for whether or not it mentions the useful insights above. Only output the insights that are not mentioned or closely talked about: [PAGE TEXT]"
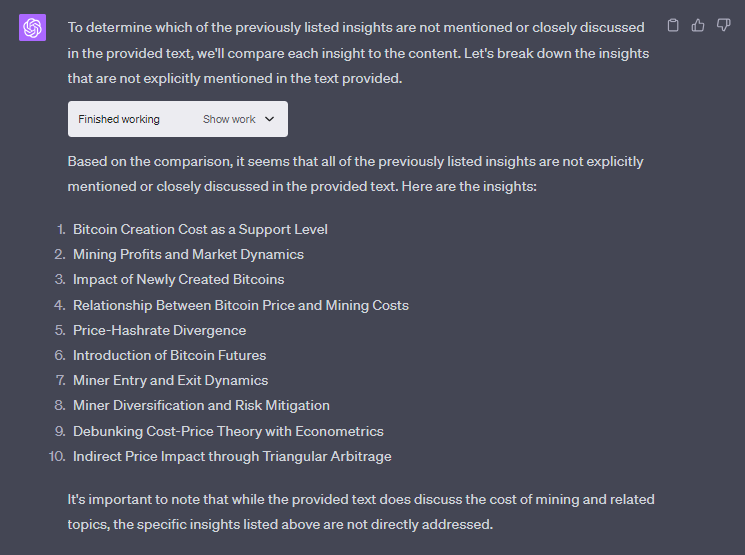
You simply copy/paste the text from your page, or your competing page, and paste it into the chat with the prompt above.
Note that the page provided does not provide any of the insights from the PDF. This page is one of the top ranking pages for that target keyword, the cost of cryptocurrency mining.
Here is the article text I referenced if you want to check.
Is it information gain though?
You can repeat this check for other top ranking pages to arrive at the consensus that no one is talking about the key points from this PDF. Thus, information gain.
And this is only one random PDF. There are infinite PDFs out there.
In some cases, you might find that pages are in fact covering some of the key points from the PDF. But the chances of that happening are fairly small.
Now you just need to use gained information in your content
Now that you have identified some potentially helpful chunks of info you could add to your page, you need to determine which insights you will use and how to use them.
Step 1: Prompt to find which insights are most relevant
"Which of these insights are the most relevant to an article covering the price of cryptocurrency mining?"

This prompt produced 6 key insights that are most relevant to my article. It also explains why they are relevant.
Now I just need to expand on these insights.
Step 2: Prompt to expand on these insights
"For each insight, create a 1 paragraph summary explaining the insight in detail. Use short sentences, simple grammar, lists, and line breaks to make it easy to comprehend."

At this point you have everything you need to create insights from this extraction. You could be a bit cheeky and just ask ChatGPT to produce an article based on these key insights, but I recommend using them as add-ons instead of standalones, if you know what I mean.
The whole point of this technique is to give you more time to make better content, by reducing high effort information gain tasks. Now it’s your job to use the insights to your advantage instead of being a content spammer.
Step 3: rinse and repeat
You could repeat this extraction process for any PDF. Most of the time you will find that the insights are not repeated around the web.
Because most people writing content for SEO are only going to reference existing web pages.
Now you try
Here’s a recap:
- Find a PDF relevant to your target keyword.
- Download the PDF and upload it to ChatGPT with the code interpreter feature enabled.
- Prompt ChatGPT to provide 10 useful insights about your target keyword from the PDF.
- Check to see if any of these insights are on the first page for your target keyword.
- If not, use ChatGPT to scan pages to see if they are using the useful insights found from the PDF.
- Use the gained information in your content.
Additional tips:
- Experiment with different prompts to squeeze juice out of PDFs.
- Be creative and experiment with different ways to use information gain to improve your content.
The whole interwebs at your fingertips
We’ve barely scratched the surface of what’s possible here. Not only are there a bajillion different prompts you could use to squeeze juice out of PDFS, but you can reference other media.
Like books, videos, images, etc.